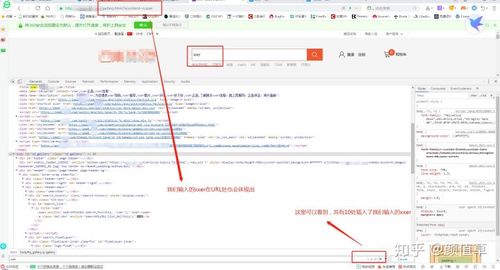
<h3>收费网站怎么绕过:深度解析与实用技巧</h3> <p>在网络世界中,许多优质资源都被集中在收费网站上,用户需要支付一定费用才能获取完整内容或高级功能。然而,面对高昂的付费壁垒,不少用户希望找到一些方法绕过这些限制,快速获得所需资源。本文将从技术角度出发,详细介绍收费网站的常见防护机制、绕过策略以及实际操作步骤,帮助用户合理利用网络资源,同时也提醒大家遵循法律法规,合理使用网络服务。</p> <h3>收费网站的核心防护机制</h3> <p>在探讨绕过方法之前,首先需要理解收费网站的主要防护措施。这些机制旨在确保内容的专属性和商业价值,常见的有:</p> <ul> <li><strong>会员验证系统:</strong>用户必须注册并登录,才能访问付费内容。验证过程可能包括邮箱验证、手机验证或第三方登录。</li> <li><strong>付费墙(Paywall):</strong>通过前端代码屏蔽未付费用户的内容,只有完成支付后,相关内容才会解锁显示。</li> <li><strong>IP和设备识别:</strong>网站会监控访问者的IP地址和设备信息,阻止非授权设备或频繁切换IP的访问行为。</li> <li><strong>动态内容加载:</strong>利用AJAX等技术,将内容分段加载,增加绕过难度。</li> <li><strong>验证码和反爬虫措施:</strong>为防止自动化爬取,网站会设置验证码或限制请求频率。</li> </ul> <h3>常用的绕过策略与技术手段</h3> <p>针对上述防护措施,用户可以采用多种技术手段实现绕过。以下是一些常见的方法及其原理:</p> <h3>模拟登录与会话管理</h3> <p>通过模拟用户登录流程,获取有效的会话Cookie或Token,从而绕过会员验证。具体步骤包括:</p> <ul> <li>使用浏览器开发者工具,观察登录请求的参数和返回的Cookie信息。</li> <li>利用脚本(如Python的Requests库)模拟登录请求,提交正确的账号和密码。</li> <li>保存登录后获得的会话Cookie,后续请求中携带该Cookie,以获得会员权限内容。</li> </ul> <p>注意:此方法需要用户掌握一定的网络请求分析和脚本编写能力,且应确保不违反法律法规。</p> <h3>破解付费墙</h3> <p>一些网站的付费墙是由前端代码控制的,用户可以通过以下手段绕过:</p> <ul> <li>利用开发者工具,直接修改网页的DOM结构,将隐藏的内容显示出来。</li> <li>拦截请求,阻止付费验证请求的返回,模拟已支付状态。</li> <li>使用扩展或脚本,自动识别并解锁隐藏内容区域(如通过Tampermonkey脚本)。</li> </ul> <p>这种方法依赖于对网页结构的理解和一定的脚本编写能力,但也存在被反制的风险,可能导致内容显示不完整或失真。</p> <h3>绕过IP和设备限制</h3> <p>当网站通过IP或设备识别限制访问时,可以采取以下措施:</p> <ul> <li>使用VPN或代理服务器,切换不同的IP地址,规避IP封锁。</li> <li>更换设备或清除浏览器缓存,避免被识别为重复访问者。</li> <li>结合使用多用户账号,避免因单一账号频繁访问而被封禁。</li> </ul> <p>然而,频繁变换IP和设备可能引起网站的警觉,需谨慎操作,避免被封禁或追踪。</p> <h3>自动化爬取与内容提取</h3> <p>对于大量内容的批量获取,自动化爬虫是一种高效手段。操作流程包括:</p> <ul> <li>分析网页结构,识别目标内容的HTML标签或API接口。</li> <li>利用爬虫工具(如Scrapy、BeautifulSoup)编写脚本,自动抓取目标内容。</li> <li>结合模拟登录和Cookie管理,确保爬取权限的持续有效。</li> <li>设置请求频率,模拟正常用户行为,避免被封禁。</li> </ul> <p>需要注意的是,爬取过程中应尊重网站的robots.txt政策,避免违法行为。</p> <h3>生活化视角下的建议与注意事项</h3> <p>虽然技术手段丰富多样,但绕过收费网站的行为存在一定的法律和道德风险。建议用户理性使用,尽量选择合法途径获取资源。例如:</p> <ul> <li>利用网站的免费试用或优惠活动,合理获取内容。</li> <li>关注内容提供商的促销信息,低价订阅或购买内容。</li> <li>使用公共图书馆或学校的合法资源,获取免费或低价的专业资料。</li> </ul> <p>技术手段应作为学习和探索的工具,而非非法获取内容的手段。任何绕过措施都应在合法合规的范围内进行,避免造成不必要的法律风险和道德争议。</p> <h3>总结</h3> <p>理解收费网站的防护机制是实现绕过的前提,通过模拟登录、修改网页内容、使用代理等多种技术手段,可以在一定程度上突破限制。然而,用户应始终坚持合法合理的原则,尊重内容创作者的权益。未来,随着技术的发展和法律法规的完善,网络资源的获取方式也会越来越丰富和规范。作为一名资深的软件下载站主编,建议广大用户在追求便利的同时,保持良好的网络道德与法律意识,共建健康的网络环境。</p> <h3>用户评价</h3> <p><strong>科技宅小王:</strong>我一直用模拟登录的方法绕过付费墙,操作简单效果明显,但要注意不要频繁请求,否则容易被封禁。</p> <p><strong>设计狮阿杰:</strong>通过修改网页DOM结构,成功解锁了部分隐藏内容,学习了不少网页结构知识,挺有趣的体验。</p> <p><strong>生活小白:</strong>刚开始不太懂,后来用VPN切换IP,配合脚本操作,终于拿到想看的资料,感觉技术门槛有点高,建议新手谨慎尝试。</p> <p><strong>互联网老兵:</strong>我觉得合理利用免费资源和促销活动更稳妥,绕过付费墙虽然方便,但要考虑版权和法律问题。</p>
立即下载<h3>收费网站怎么绕过:深度解析与实用技巧</h3> <p>在网络世界中,许多优质资源都被集中在收费网站上,用户需要支付一定费用才能获取完整内容或高级功能。然而,面对高昂的付费壁垒,不少用户希望找到一些方法绕过这些限制,快速获得所需资源。本文将从技术角度出发,详细介绍收费网站的常见防护机制、绕过策略以及实际操作步骤,帮助用户合理利用网络资源,同时也提醒大家遵循法律法规,合理使用网络服务。</p> <h3>收费网站的核心防护机制</h3> <p>在探讨绕过方法之前,首先需要理解收费网站的主要防护措施。这些机制旨在确保内容的专属性和商业价值,常见的有:</p> <ul> <li><strong>会员验证系统:</strong>用户必须注册并登录,才能访问付费内容。验证过程可能包括邮箱验证、手机验证或第三方登录。</li> <li><strong>付费墙(Paywall):</strong>通过前端代码屏蔽未付费用户的内容,只有完成支付后,相关内容才会解锁显示。</li> <li><strong>IP和设备识别:</strong>网站会监控访问者的IP地址和设备信息,阻止非授权设备或频繁切换IP的访问行为。</li> <li><strong>动态内容加载:</strong>利用AJAX等技术,将内容分段加载,增加绕过难度。</li> <li><strong>验证码和反爬虫措施:</strong>为防止自动化爬取,网站会设置验证码或限制请求频率。</li> </ul> <h3>常用的绕过策略与技术手段</h3> <p>针对上述防护措施,用户可以采用多种技术手段实现绕过。以下是一些常见的方法及其原理:</p> <h3>模拟登录与会话管理</h3> <p>通过模拟用户登录流程,获取有效的会话Cookie或Token,从而绕过会员验证。具体步骤包括:</p> <ul> <li>使用浏览器开发者工具,观察登录请求的参数和返回的Cookie信息。</li> <li>利用脚本(如Python的Requests库)模拟登录请求,提交正确的账号和密码。</li> <li>保存登录后获得的会话Cookie,后续请求中携带该Cookie,以获得会员权限内容。</li> </ul> <p>注意:此方法需要用户掌握一定的网络请求分析和脚本编写能力,且应确保不违反法律法规。</p> <h3>破解付费墙</h3> <p>一些网站的付费墙是由前端代码控制的,用户可以通过以下手段绕过:</p> <ul> <li>利用开发者工具,直接修改网页的DOM结构,将隐藏的内容显示出来。</li> <li>拦截请求,阻止付费验证请求的返回,模拟已支付状态。</li> <li>使用扩展或脚本,自动识别并解锁隐藏内容区域(如通过Tampermonkey脚本)。</li> </ul> <p>这种方法依赖于对网页结构的理解和一定的脚本编写能力,但也存在被反制的风险,可能导致内容显示不完整或失真。</p> <h3>绕过IP和设备限制</h3> <p>当网站通过IP或设备识别限制访问时,可以采取以下措施:</p> <ul> <li>使用VPN或代理服务器,切换不同的IP地址,规避IP封锁。</li> <li>更换设备或清除浏览器缓存,避免被识别为重复访问者。</li> <li>结合使用多用户账号,避免因单一账号频繁访问而被封禁。</li> </ul> <p>然而,频繁变换IP和设备可能引起网站的警觉,需谨慎操作,避免被封禁或追踪。</p> <h3>自动化爬取与内容提取</h3> <p>对于大量内容的批量获取,自动化爬虫是一种高效手段。操作流程包括:</p> <ul> <li>分析网页结构,识别目标内容的HTML标签或API接口。</li> <li>利用爬虫工具(如Scrapy、BeautifulSoup)编写脚本,自动抓取目标内容。</li> <li>结合模拟登录和Cookie管理,确保爬取权限的持续有效。</li> <li>设置请求频率,模拟正常用户行为,避免被封禁。</li> </ul> <p>需要注意的是,爬取过程中应尊重网站的robots.txt政策,避免违法行为。</p> <h3>生活化视角下的建议与注意事项</h3> <p>虽然技术手段丰富多样,但绕过收费网站的行为存在一定的法律和道德风险。建议用户理性使用,尽量选择合法途径获取资源。例如:</p> <ul> <li>利用网站的免费试用或优惠活动,合理获取内容。</li> <li>关注内容提供商的促销信息,低价订阅或购买内容。</li> <li>使用公共图书馆或学校的合法资源,获取免费或低价的专业资料。</li> </ul> <p>技术手段应作为学习和探索的工具,而非非法获取内容的手段。任何绕过措施都应在合法合规的范围内进行,避免造成不必要的法律风险和道德争议。</p> <h3>总结</h3> <p>理解收费网站的防护机制是实现绕过的前提,通过模拟登录、修改网页内容、使用代理等多种技术手段,可以在一定程度上突破限制。然而,用户应始终坚持合法合理的原则,尊重内容创作者的权益。未来,随着技术的发展和法律法规的完善,网络资源的获取方式也会越来越丰富和规范。作为一名资深的软件下载站主编,建议广大用户在追求便利的同时,保持良好的网络道德与法律意识,共建健康的网络环境。</p> <h3>用户评价</h3> <p><strong>科技宅小王:</strong>我一直用模拟登录的方法绕过付费墙,操作简单效果明显,但要注意不要频繁请求,否则容易被封禁。</p> <p><strong>设计狮阿杰:</strong>通过修改网页DOM结构,成功解锁了部分隐藏内容,学习了不少网页结构知识,挺有趣的体验。</p> <p><strong>生活小白:</strong>刚开始不太懂,后来用VPN切换IP,配合脚本操作,终于拿到想看的资料,感觉技术门槛有点高,建议新手谨慎尝试。</p> <p><strong>互联网老兵:</strong>我觉得合理利用免费资源和促销活动更稳妥,绕过付费墙虽然方便,但要考虑版权和法律问题。</p>
<h3>收费网站怎么绕过:深度解析与实用技巧</h3> <p>在网络世界中,许多优质资源都被集中在收费网站上,用户需要支付一定费用才能获取完整内容或高级功能。然而,面对高昂的付费壁垒,不少用户希望找到一些方法绕过这些限制,快速获得所需资源。本文将从技术角度出发,详细介绍收费网站的常见防护机制、绕过策略以及实际操作步骤,帮助用户合理利用网络资源,同时也提醒大家遵循法律法规,合理使用网络服务。</p> <h3>收费网站的核心防护机制</h3> <p>在探讨绕过方法之前,首先需要理解收费网站的主要防护措施。这些机制旨在确保内容的专属性和商业价值,常见的有:</p> <ul> <li><strong>会员验证系统:</strong>用户必须注册并登录,才能访问付费内容。验证过程可能包括邮箱验证、手机验证或第三方登录。</li> <li><strong>付费墙(Paywall):</strong>通过前端代码屏蔽未付费用户的内容,只有完成支付后,相关内容才会解锁显示。</li> <li><strong>IP和设备识别:</strong>网站会监控访问者的IP地址和设备信息,阻止非授权设备或频繁切换IP的访问行为。</li> <li><strong>动态内容加载:</strong>利用AJAX等技术,将内容分段加载,增加绕过难度。</li> <li><strong>验证码和反爬虫措施:</strong>为防止自动化爬取,网站会设置验证码或限制请求频率。</li> </ul> <h3>常用的绕过策略与技术手段</h3> <p>针对上述防护措施,用户可以采用多种技术手段实现绕过。以下是一些常见的方法及其原理:</p> <h3>模拟登录与会话管理</h3> <p>通过模拟用户登录流程,获取有效的会话Cookie或Token,从而绕过会员验证。具体步骤包括:</p> <ul> <li>使用浏览器开发者工具,观察登录请求的参数和返回的Cookie信息。</li> <li>利用脚本(如Python的Requests库)模拟登录请求,提交正确的账号和密码。</li> <li>保存登录后获得的会话Cookie,后续请求中携带该Cookie,以获得会员权限内容。</li> </ul> <p>注意:此方法需要用户掌握一定的网络请求分析和脚本编写能力,且应确保不违反法律法规。</p> <h3>破解付费墙</h3> <p>一些网站的付费墙是由前端代码控制的,用户可以通过以下手段绕过:</p> <ul> <li>利用开发者工具,直接修改网页的DOM结构,将隐藏的内容显示出来。</li> <li>拦截请求,阻止付费验证请求的返回,模拟已支付状态。</li> <li>使用扩展或脚本,自动识别并解锁隐藏内容区域(如通过Tampermonkey脚本)。</li> </ul> <p>这种方法依赖于对网页结构的理解和一定的脚本编写能力,但也存在被反制的风险,可能导致内容显示不完整或失真。</p> <h3>绕过IP和设备限制</h3> <p>当网站通过IP或设备识别限制访问时,可以采取以下措施:</p> <ul> <li>使用VPN或代理服务器,切换不同的IP地址,规避IP封锁。</li> <li>更换设备或清除浏览器缓存,避免被识别为重复访问者。</li> <li>结合使用多用户账号,避免因单一账号频繁访问而被封禁。</li> </ul> <p>然而,频繁变换IP和设备可能引起网站的警觉,需谨慎操作,避免被封禁或追踪。</p> <h3>自动化爬取与内容提取</h3> <p>对于大量内容的批量获取,自动化爬虫是一种高效手段。操作流程包括:</p> <ul> <li>分析网页结构,识别目标内容的HTML标签或API接口。</li> <li>利用爬虫工具(如Scrapy、BeautifulSoup)编写脚本,自动抓取目标内容。</li> <li>结合模拟登录和Cookie管理,确保爬取权限的持续有效。</li> <li>设置请求频率,模拟正常用户行为,避免被封禁。</li> </ul> <p>需要注意的是,爬取过程中应尊重网站的robots.txt政策,避免违法行为。</p> <h3>生活化视角下的建议与注意事项</h3> <p>虽然技术手段丰富多样,但绕过收费网站的行为存在一定的法律和道德风险。建议用户理性使用,尽量选择合法途径获取资源。例如:</p> <ul> <li>利用网站的免费试用或优惠活动,合理获取内容。</li> <li>关注内容提供商的促销信息,低价订阅或购买内容。</li> <li>使用公共图书馆或学校的合法资源,获取免费或低价的专业资料。</li> </ul> <p>技术手段应作为学习和探索的工具,而非非法获取内容的手段。任何绕过措施都应在合法合规的范围内进行,避免造成不必要的法律风险和道德争议。</p> <h3>总结</h3> <p>理解收费网站的防护机制是实现绕过的前提,通过模拟登录、修改网页内容、使用代理等多种技术手段,可以在一定程度上突破限制。然而,用户应始终坚持合法合理的原则,尊重内容创作者的权益。未来,随着技术的发展和法律法规的完善,网络资源的获取方式也会越来越丰富和规范。作为一名资深的软件下载站主编,建议广大用户在追求便利的同时,保持良好的网络道德与法律意识,共建健康的网络环境。</p> <h3>用户评价</h3> <p><strong>科技宅小王:</strong>我一直用模拟登录的方法绕过付费墙,操作简单效果明显,但要注意不要频繁请求,否则容易被封禁。</p> <p><strong>设计狮阿杰:</strong>通过修改网页DOM结构,成功解锁了部分隐藏内容,学习了不少网页结构知识,挺有趣的体验。</p> <p><strong>生活小白:</strong>刚开始不太懂,后来用VPN切换IP,配合脚本操作,终于拿到想看的资料,感觉技术门槛有点高,建议新手谨慎尝试。</p> <p><strong>互联网老兵:</strong>我觉得合理利用免费资源和促销活动更稳妥,绕过付费墙虽然方便,但要考虑版权和法律问题。</p>
<h3>收费网站怎么绕过:深度解析与实用技巧</h3> <p>在网络世界中,许多优质资源都被集中在收费网站上,用户需要支付一定费用才能获取完整内容或高级功能。然而,面对高昂的付费壁垒,不少用户希望找到一些方法绕过这些限制,快速获得所需资源。本文将从技术角度出发,详细介绍收费网站的常见防护机制、绕过策略以及实际操作步骤,帮助用户合理利用网络资源,同时也提醒大家遵循法律法规,合理使用网络服务。</p> <h3>收费网站的核心防护机制</h3> <p>在探讨绕过方法之前,首先需要理解收费网站的主要防护措施。这些机制旨在确保内容的专属性和商业价值,常见的有:</p> <ul> <li><strong>会员验证系统:</strong>用户必须注册并登录,才能访问付费内容。验证过程可能包括邮箱验证、手机验证或第三方登录。</li> <li><strong>付费墙(Paywall):</strong>通过前端代码屏蔽未付费用户的内容,只有完成支付后,相关内容才会解锁显示。</li> <li><strong>IP和设备识别:</strong>网站会监控访问者的IP地址和设备信息,阻止非授权设备或频繁切换IP的访问行为。</li> <li><strong>动态内容加载:</strong>利用AJAX等技术,将内容分段加载,增加绕过难度。</li> <li><strong>验证码和反爬虫措施:</strong>为防止自动化爬取,网站会设置验证码或限制请求频率。</li> </ul> <h3>常用的绕过策略与技术手段</h3> <p>针对上述防护措施,用户可以采用多种技术手段实现绕过。以下是一些常见的方法及其原理:</p> <h3>模拟登录与会话管理</h3> <p>通过模拟用户登录流程,获取有效的会话Cookie或Token,从而绕过会员验证。具体步骤包括:</p> <ul> <li>使用浏览器开发者工具,观察登录请求的参数和返回的Cookie信息。</li> <li>利用脚本(如Python的Requests库)模拟登录请求,提交正确的账号和密码。</li> <li>保存登录后获得的会话Cookie,后续请求中携带该Cookie,以获得会员权限内容。</li> </ul> <p>注意:此方法需要用户掌握一定的网络请求分析和脚本编写能力,且应确保不违反法律法规。</p> <h3>破解付费墙</h3> <p>一些网站的付费墙是由前端代码控制的,用户可以通过以下手段绕过:</p> <ul> <li>利用开发者工具,直接修改网页的DOM结构,将隐藏的内容显示出来。</li> <li>拦截请求,阻止付费验证请求的返回,模拟已支付状态。</li> <li>使用扩展或脚本,自动识别并解锁隐藏内容区域(如通过Tampermonkey脚本)。</li> </ul> <p>这种方法依赖于对网页结构的理解和一定的脚本编写能力,但也存在被反制的风险,可能导致内容显示不完整或失真。</p> <h3>绕过IP和设备限制</h3> <p>当网站通过IP或设备识别限制访问时,可以采取以下措施:</p> <ul> <li>使用VPN或代理服务器,切换不同的IP地址,规避IP封锁。</li> <li>更换设备或清除浏览器缓存,避免被识别为重复访问者。</li> <li>结合使用多用户账号,避免因单一账号频繁访问而被封禁。</li> </ul> <p>然而,频繁变换IP和设备可能引起网站的警觉,需谨慎操作,避免被封禁或追踪。</p> <h3>自动化爬取与内容提取</h3> <p>对于大量内容的批量获取,自动化爬虫是一种高效手段。操作流程包括:</p> <ul> <li>分析网页结构,识别目标内容的HTML标签或API接口。</li> <li>利用爬虫工具(如Scrapy、BeautifulSoup)编写脚本,自动抓取目标内容。</li> <li>结合模拟登录和Cookie管理,确保爬取权限的持续有效。</li> <li>设置请求频率,模拟正常用户行为,避免被封禁。</li> </ul> <p>需要注意的是,爬取过程中应尊重网站的robots.txt政策,避免违法行为。</p> <h3>生活化视角下的建议与注意事项</h3> <p>虽然技术手段丰富多样,但绕过收费网站的行为存在一定的法律和道德风险。建议用户理性使用,尽量选择合法途径获取资源。例如:</p> <ul> <li>利用网站的免费试用或优惠活动,合理获取内容。</li> <li>关注内容提供商的促销信息,低价订阅或购买内容。</li> <li>使用公共图书馆或学校的合法资源,获取免费或低价的专业资料。</li> </ul> <p>技术手段应作为学习和探索的工具,而非非法获取内容的手段。任何绕过措施都应在合法合规的范围内进行,避免造成不必要的法律风险和道德争议。</p> <h3>总结</h3> <p>理解收费网站的防护机制是实现绕过的前提,通过模拟登录、修改网页内容、使用代理等多种技术手段,可以在一定程度上突破限制。然而,用户应始终坚持合法合理的原则,尊重内容创作者的权益。未来,随着技术的发展和法律法规的完善,网络资源的获取方式也会越来越丰富和规范。作为一名资深的软件下载站主编,建议广大用户在追求便利的同时,保持良好的网络道德与法律意识,共建健康的网络环境。</p> <h3>用户评价</h3> <p><strong>科技宅小王:</strong>我一直用模拟登录的方法绕过付费墙,操作简单效果明显,但要注意不要频繁请求,否则容易被封禁。</p> <p><strong>设计狮阿杰:</strong>通过修改网页DOM结构,成功解锁了部分隐藏内容,学习了不少网页结构知识,挺有趣的体验。</p> <p><strong>生活小白:</strong>刚开始不太懂,后来用VPN切换IP,配合脚本操作,终于拿到想看的资料,感觉技术门槛有点高,建议新手谨慎尝试。</p> <p><strong>互联网老兵:</strong>我觉得合理利用免费资源和促销活动更稳妥,绕过付费墙虽然方便,但要考虑版权和法律问题。</p>
<h3>收费网站怎么绕过:深度解析与实用技巧</h3> <p>在网络世界中,许多优质资源都被集中在收费网站上,用户需要支付一定费用才能获取完整内容或高级功能。然而,面对高昂的付费壁垒,不少用户希望找到一些方法绕过这些限制,快速获得所需资源。本文将从技术角度出发,详细介绍收费网站的常见防护机制、绕过策略以及实际操作步骤,帮助用户合理利用网络资源,同时也提醒大家遵循法律法规,合理使用网络服务。</p> <h3>收费网站的核心防护机制</h3> <p>在探讨绕过方法之前,首先需要理解收费网站的主要防护措施。这些机制旨在确保内容的专属性和商业价值,常见的有:</p> <ul> <li><strong>会员验证系统:</strong>用户必须注册并登录,才能访问付费内容。验证过程可能包括邮箱验证、手机验证或第三方登录。</li> <li><strong>付费墙(Paywall):</strong>通过前端代码屏蔽未付费用户的内容,只有完成支付后,相关内容才会解锁显示。</li> <li><strong>IP和设备识别:</strong>网站会监控访问者的IP地址和设备信息,阻止非授权设备或频繁切换IP的访问行为。</li> <li><strong>动态内容加载:</strong>利用AJAX等技术,将内容分段加载,增加绕过难度。</li> <li><strong>验证码和反爬虫措施:</strong>为防止自动化爬取,网站会设置验证码或限制请求频率。</li> </ul> <h3>常用的绕过策略与技术手段</h3> <p>针对上述防护措施,用户可以采用多种技术手段实现绕过。以下是一些常见的方法及其原理:</p> <h3>模拟登录与会话管理</h3> <p>通过模拟用户登录流程,获取有效的会话Cookie或Token,从而绕过会员验证。具体步骤包括:</p> <ul> <li>使用浏览器开发者工具,观察登录请求的参数和返回的Cookie信息。</li> <li>利用脚本(如Python的Requests库)模拟登录请求,提交正确的账号和密码。</li> <li>保存登录后获得的会话Cookie,后续请求中携带该Cookie,以获得会员权限内容。</li> </ul> <p>注意:此方法需要用户掌握一定的网络请求分析和脚本编写能力,且应确保不违反法律法规。</p> <h3>破解付费墙</h3> <p>一些网站的付费墙是由前端代码控制的,用户可以通过以下手段绕过:</p> <ul> <li>利用开发者工具,直接修改网页的DOM结构,将隐藏的内容显示出来。</li> <li>拦截请求,阻止付费验证请求的返回,模拟已支付状态。</li> <li>使用扩展或脚本,自动识别并解锁隐藏内容区域(如通过Tampermonkey脚本)。</li> </ul> <p>这种方法依赖于对网页结构的理解和一定的脚本编写能力,但也存在被反制的风险,可能导致内容显示不完整或失真。</p> <h3>绕过IP和设备限制</h3> <p>当网站通过IP或设备识别限制访问时,可以采取以下措施:</p> <ul> <li>使用VPN或代理服务器,切换不同的IP地址,规避IP封锁。</li> <li>更换设备或清除浏览器缓存,避免被识别为重复访问者。</li> <li>结合使用多用户账号,避免因单一账号频繁访问而被封禁。</li> </ul> <p>然而,频繁变换IP和设备可能引起网站的警觉,需谨慎操作,避免被封禁或追踪。</p> <h3>自动化爬取与内容提取</h3> <p>对于大量内容的批量获取,自动化爬虫是一种高效手段。操作流程包括:</p> <ul> <li>分析网页结构,识别目标内容的HTML标签或API接口。</li> <li>利用爬虫工具(如Scrapy、BeautifulSoup)编写脚本,自动抓取目标内容。</li> <li>结合模拟登录和Cookie管理,确保爬取权限的持续有效。</li> <li>设置请求频率,模拟正常用户行为,避免被封禁。</li> </ul> <p>需要注意的是,爬取过程中应尊重网站的robots.txt政策,避免违法行为。</p> <h3>生活化视角下的建议与注意事项</h3> <p>虽然技术手段丰富多样,但绕过收费网站的行为存在一定的法律和道德风险。建议用户理性使用,尽量选择合法途径获取资源。例如:</p> <ul> <li>利用网站的免费试用或优惠活动,合理获取内容。</li> <li>关注内容提供商的促销信息,低价订阅或购买内容。</li> <li>使用公共图书馆或学校的合法资源,获取免费或低价的专业资料。</li> </ul> <p>技术手段应作为学习和探索的工具,而非非法获取内容的手段。任何绕过措施都应在合法合规的范围内进行,避免造成不必要的法律风险和道德争议。</p> <h3>总结</h3> <p>理解收费网站的防护机制是实现绕过的前提,通过模拟登录、修改网页内容、使用代理等多种技术手段,可以在一定程度上突破限制。然而,用户应始终坚持合法合理的原则,尊重内容创作者的权益。未来,随着技术的发展和法律法规的完善,网络资源的获取方式也会越来越丰富和规范。作为一名资深的软件下载站主编,建议广大用户在追求便利的同时,保持良好的网络道德与法律意识,共建健康的网络环境。</p> <h3>用户评价</h3> <p><strong>科技宅小王:</strong>我一直用模拟登录的方法绕过付费墙,操作简单效果明显,但要注意不要频繁请求,否则容易被封禁。</p> <p><strong>设计狮阿杰:</strong>通过修改网页DOM结构,成功解锁了部分隐藏内容,学习了不少网页结构知识,挺有趣的体验。</p> <p><strong>生活小白:</strong>刚开始不太懂,后来用VPN切换IP,配合脚本操作,终于拿到想看的资料,感觉技术门槛有点高,建议新手谨慎尝试。</p> <p><strong>互联网老兵:</strong>我觉得合理利用免费资源和促销活动更稳妥,绕过付费墙虽然方便,但要考虑版权和法律问题。</p>
<h3>收费网站怎么绕过:深度解析与实用技巧</h3> <p>在网络世界中,许多优质资源都被集中在收费网站上,用户需要支付一定费用才能获取完整内容或高级功能。然而,面对高昂的付费壁垒,不少用户希望找到一些方法绕过这些限制,快速获得所需资源。本文将从技术角度出发,详细介绍收费网站的常见防护机制、绕过策略以及实际操作步骤,帮助用户合理利用网络资源,同时也提醒大家遵循法律法规,合理使用网络服务。</p> <h3>收费网站的核心防护机制</h3> <p>在探讨绕过方法之前,首先需要理解收费网站的主要防护措施。这些机制旨在确保内容的专属性和商业价值,常见的有:</p> <ul> <li><strong>会员验证系统:</strong>用户必须注册并登录,才能访问付费内容。验证过程可能包括邮箱验证、手机验证或第三方登录。</li> <li><strong>付费墙(Paywall):</strong>通过前端代码屏蔽未付费用户的内容,只有完成支付后,相关内容才会解锁显示。</li> <li><strong>IP和设备识别:</strong>网站会监控访问者的IP地址和设备信息,阻止非授权设备或频繁切换IP的访问行为。</li> <li><strong>动态内容加载:</strong>利用AJAX等技术,将内容分段加载,增加绕过难度。</li> <li><strong>验证码和反爬虫措施:</strong>为防止自动化爬取,网站会设置验证码或限制请求频率。</li> </ul> <h3>常用的绕过策略与技术手段</h3> <p>针对上述防护措施,用户可以采用多种技术手段实现绕过。以下是一些常见的方法及其原理:</p> <h3>模拟登录与会话管理</h3> <p>通过模拟用户登录流程,获取有效的会话Cookie或Token,从而绕过会员验证。具体步骤包括:</p> <ul> <li>使用浏览器开发者工具,观察登录请求的参数和返回的Cookie信息。</li> <li>利用脚本(如Python的Requests库)模拟登录请求,提交正确的账号和密码。</li> <li>保存登录后获得的会话Cookie,后续请求中携带该Cookie,以获得会员权限内容。</li> </ul> <p>注意:此方法需要用户掌握一定的网络请求分析和脚本编写能力,且应确保不违反法律法规。</p> <h3>破解付费墙</h3> <p>一些网站的付费墙是由前端代码控制的,用户可以通过以下手段绕过:</p> <ul> <li>利用开发者工具,直接修改网页的DOM结构,将隐藏的内容显示出来。</li> <li>拦截请求,阻止付费验证请求的返回,模拟已支付状态。</li> <li>使用扩展或脚本,自动识别并解锁隐藏内容区域(如通过Tampermonkey脚本)。</li> </ul> <p>这种方法依赖于对网页结构的理解和一定的脚本编写能力,但也存在被反制的风险,可能导致内容显示不完整或失真。</p> <h3>绕过IP和设备限制</h3> <p>当网站通过IP或设备识别限制访问时,可以采取以下措施:</p> <ul> <li>使用VPN或代理服务器,切换不同的IP地址,规避IP封锁。</li> <li>更换设备或清除浏览器缓存,避免被识别为重复访问者。</li> <li>结合使用多用户账号,避免因单一账号频繁访问而被封禁。</li> </ul> <p>然而,频繁变换IP和设备可能引起网站的警觉,需谨慎操作,避免被封禁或追踪。</p> <h3>自动化爬取与内容提取</h3> <p>对于大量内容的批量获取,自动化爬虫是一种高效手段。操作流程包括:</p> <ul> <li>分析网页结构,识别目标内容的HTML标签或API接口。</li> <li>利用爬虫工具(如Scrapy、BeautifulSoup)编写脚本,自动抓取目标内容。</li> <li>结合模拟登录和Cookie管理,确保爬取权限的持续有效。</li> <li>设置请求频率,模拟正常用户行为,避免被封禁。</li> </ul> <p>需要注意的是,爬取过程中应尊重网站的robots.txt政策,避免违法行为。</p> <h3>生活化视角下的建议与注意事项</h3> <p>虽然技术手段丰富多样,但绕过收费网站的行为存在一定的法律和道德风险。建议用户理性使用,尽量选择合法途径获取资源。例如:</p> <ul> <li>利用网站的免费试用或优惠活动,合理获取内容。</li> <li>关注内容提供商的促销信息,低价订阅或购买内容。</li> <li>使用公共图书馆或学校的合法资源,获取免费或低价的专业资料。</li> </ul> <p>技术手段应作为学习和探索的工具,而非非法获取内容的手段。任何绕过措施都应在合法合规的范围内进行,避免造成不必要的法律风险和道德争议。</p> <h3>总结</h3> <p>理解收费网站的防护机制是实现绕过的前提,通过模拟登录、修改网页内容、使用代理等多种技术手段,可以在一定程度上突破限制。然而,用户应始终坚持合法合理的原则,尊重内容创作者的权益。未来,随着技术的发展和法律法规的完善,网络资源的获取方式也会越来越丰富和规范。作为一名资深的软件下载站主编,建议广大用户在追求便利的同时,保持良好的网络道德与法律意识,共建健康的网络环境。</p> <h3>用户评价</h3> <p><strong>科技宅小王:</strong>我一直用模拟登录的方法绕过付费墙,操作简单效果明显,但要注意不要频繁请求,否则容易被封禁。</p> <p><strong>设计狮阿杰:</strong>通过修改网页DOM结构,成功解锁了部分隐藏内容,学习了不少网页结构知识,挺有趣的体验。</p> <p><strong>生活小白:</strong>刚开始不太懂,后来用VPN切换IP,配合脚本操作,终于拿到想看的资料,感觉技术门槛有点高,建议新手谨慎尝试。</p> <p><strong>互联网老兵:</strong>我觉得合理利用免费资源和促销活动更稳妥,绕过付费墙虽然方便,但要考虑版权和法律问题。</p>
<h3>收费网站怎么绕过:深度解析与实用技巧</h3> <p>在网络世界中,许多优质资源都被集中在收费网站上,用户需要支付一定费用才能获取完整内容或高级功能。然而,面对高昂的付费壁垒,不少用户希望找到一些方法绕过这些限制,快速获得所需资源。本文将从技术角度出发,详细介绍收费网站的常见防护机制、绕过策略以及实际操作步骤,帮助用户合理利用网络资源,同时也提醒大家遵循法律法规,合理使用网络服务。</p> <h3>收费网站的核心防护机制</h3> <p>在探讨绕过方法之前,首先需要理解收费网站的主要防护措施。这些机制旨在确保内容的专属性和商业价值,常见的有:</p> <ul> <li><strong>会员验证系统:</strong>用户必须注册并登录,才能访问付费内容。验证过程可能包括邮箱验证、手机验证或第三方登录。</li> <li><strong>付费墙(Paywall):</strong>通过前端代码屏蔽未付费用户的内容,只有完成支付后,相关内容才会解锁显示。</li> <li><strong>IP和设备识别:</strong>网站会监控访问者的IP地址和设备信息,阻止非授权设备或频繁切换IP的访问行为。</li> <li><strong>动态内容加载:</strong>利用AJAX等技术,将内容分段加载,增加绕过难度。</li> <li><strong>验证码和反爬虫措施:</strong>为防止自动化爬取,网站会设置验证码或限制请求频率。</li> </ul> <h3>常用的绕过策略与技术手段</h3> <p>针对上述防护措施,用户可以采用多种技术手段实现绕过。以下是一些常见的方法及其原理:</p> <h3>模拟登录与会话管理</h3> <p>通过模拟用户登录流程,获取有效的会话Cookie或Token,从而绕过会员验证。具体步骤包括:</p> <ul> <li>使用浏览器开发者工具,观察登录请求的参数和返回的Cookie信息。</li> <li>利用脚本(如Python的Requests库)模拟登录请求,提交正确的账号和密码。</li> <li>保存登录后获得的会话Cookie,后续请求中携带该Cookie,以获得会员权限内容。</li> </ul> <p>注意:此方法需要用户掌握一定的网络请求分析和脚本编写能力,且应确保不违反法律法规。</p> <h3>破解付费墙</h3> <p>一些网站的付费墙是由前端代码控制的,用户可以通过以下手段绕过:</p> <ul> <li>利用开发者工具,直接修改网页的DOM结构,将隐藏的内容显示出来。</li> <li>拦截请求,阻止付费验证请求的返回,模拟已支付状态。</li> <li>使用扩展或脚本,自动识别并解锁隐藏内容区域(如通过Tampermonkey脚本)。</li> </ul> <p>这种方法依赖于对网页结构的理解和一定的脚本编写能力,但也存在被反制的风险,可能导致内容显示不完整或失真。</p> <h3>绕过IP和设备限制</h3> <p>当网站通过IP或设备识别限制访问时,可以采取以下措施:</p> <ul> <li>使用VPN或代理服务器,切换不同的IP地址,规避IP封锁。</li> <li>更换设备或清除浏览器缓存,避免被识别为重复访问者。</li> <li>结合使用多用户账号,避免因单一账号频繁访问而被封禁。</li> </ul> <p>然而,频繁变换IP和设备可能引起网站的警觉,需谨慎操作,避免被封禁或追踪。</p> <h3>自动化爬取与内容提取</h3> <p>对于大量内容的批量获取,自动化爬虫是一种高效手段。操作流程包括:</p> <ul> <li>分析网页结构,识别目标内容的HTML标签或API接口。</li> <li>利用爬虫工具(如Scrapy、BeautifulSoup)编写脚本,自动抓取目标内容。</li> <li>结合模拟登录和Cookie管理,确保爬取权限的持续有效。</li> <li>设置请求频率,模拟正常用户行为,避免被封禁。</li> </ul> <p>需要注意的是,爬取过程中应尊重网站的robots.txt政策,避免违法行为。</p> <h3>生活化视角下的建议与注意事项</h3> <p>虽然技术手段丰富多样,但绕过收费网站的行为存在一定的法律和道德风险。建议用户理性使用,尽量选择合法途径获取资源。例如:</p> <ul> <li>利用网站的免费试用或优惠活动,合理获取内容。</li> <li>关注内容提供商的促销信息,低价订阅或购买内容。</li> <li>使用公共图书馆或学校的合法资源,获取免费或低价的专业资料。</li> </ul> <p>技术手段应作为学习和探索的工具,而非非法获取内容的手段。任何绕过措施都应在合法合规的范围内进行,避免造成不必要的法律风险和道德争议。</p> <h3>总结</h3> <p>理解收费网站的防护机制是实现绕过的前提,通过模拟登录、修改网页内容、使用代理等多种技术手段,可以在一定程度上突破限制。然而,用户应始终坚持合法合理的原则,尊重内容创作者的权益。未来,随着技术的发展和法律法规的完善,网络资源的获取方式也会越来越丰富和规范。作为一名资深的软件下载站主编,建议广大用户在追求便利的同时,保持良好的网络道德与法律意识,共建健康的网络环境。</p> <h3>用户评价</h3> <p><strong>科技宅小王:</strong>我一直用模拟登录的方法绕过付费墙,操作简单效果明显,但要注意不要频繁请求,否则容易被封禁。</p> <p><strong>设计狮阿杰:</strong>通过修改网页DOM结构,成功解锁了部分隐藏内容,学习了不少网页结构知识,挺有趣的体验。</p> <p><strong>生活小白:</strong>刚开始不太懂,后来用VPN切换IP,配合脚本操作,终于拿到想看的资料,感觉技术门槛有点高,建议新手谨慎尝试。</p> <p><strong>互联网老兵:</strong>我觉得合理利用免费资源和促销活动更稳妥,绕过付费墙虽然方便,但要考虑版权和法律问题。</p>
<h3>收费网站怎么绕过:深度解析与实用技巧</h3> <p>在网络世界中,许多优质资源都被集中在收费网站上,用户需要支付一定费用才能获取完整内容或高级功能。然而,面对高昂的付费壁垒,不少用户希望找到一些方法绕过这些限制,快速获得所需资源。本文将从技术角度出发,详细介绍收费网站的常见防护机制、绕过策略以及实际操作步骤,帮助用户合理利用网络资源,同时也提醒大家遵循法律法规,合理使用网络服务。</p> <h3>收费网站的核心防护机制</h3> <p>在探讨绕过方法之前,首先需要理解收费网站的主要防护措施。这些机制旨在确保内容的专属性和商业价值,常见的有:</p> <ul> <li><strong>会员验证系统:</strong>用户必须注册并登录,才能访问付费内容。验证过程可能包括邮箱验证、手机验证或第三方登录。</li> <li><strong>付费墙(Paywall):</strong>通过前端代码屏蔽未付费用户的内容,只有完成支付后,相关内容才会解锁显示。</li> <li><strong>IP和设备识别:</strong>网站会监控访问者的IP地址和设备信息,阻止非授权设备或频繁切换IP的访问行为。</li> <li><strong>动态内容加载:</strong>利用AJAX等技术,将内容分段加载,增加绕过难度。</li> <li><strong>验证码和反爬虫措施:</strong>为防止自动化爬取,网站会设置验证码或限制请求频率。</li> </ul> <h3>常用的绕过策略与技术手段</h3> <p>针对上述防护措施,用户可以采用多种技术手段实现绕过。以下是一些常见的方法及其原理:</p> <h3>模拟登录与会话管理</h3> <p>通过模拟用户登录流程,获取有效的会话Cookie或Token,从而绕过会员验证。具体步骤包括:</p> <ul> <li>使用浏览器开发者工具,观察登录请求的参数和返回的Cookie信息。</li> <li>利用脚本(如Python的Requests库)模拟登录请求,提交正确的账号和密码。</li> <li>保存登录后获得的会话Cookie,后续请求中携带该Cookie,以获得会员权限内容。</li> </ul> <p>注意:此方法需要用户掌握一定的网络请求分析和脚本编写能力,且应确保不违反法律法规。</p> <h3>破解付费墙</h3> <p>一些网站的付费墙是由前端代码控制的,用户可以通过以下手段绕过:</p> <ul> <li>利用开发者工具,直接修改网页的DOM结构,将隐藏的内容显示出来。</li> <li>拦截请求,阻止付费验证请求的返回,模拟已支付状态。</li> <li>使用扩展或脚本,自动识别并解锁隐藏内容区域(如通过Tampermonkey脚本)。</li> </ul> <p>这种方法依赖于对网页结构的理解和一定的脚本编写能力,但也存在被反制的风险,可能导致内容显示不完整或失真。</p> <h3>绕过IP和设备限制</h3> <p>当网站通过IP或设备识别限制访问时,可以采取以下措施:</p> <ul> <li>使用VPN或代理服务器,切换不同的IP地址,规避IP封锁。</li> <li>更换设备或清除浏览器缓存,避免被识别为重复访问者。</li> <li>结合使用多用户账号,避免因单一账号频繁访问而被封禁。</li> </ul> <p>然而,频繁变换IP和设备可能引起网站的警觉,需谨慎操作,避免被封禁或追踪。</p> <h3>自动化爬取与内容提取</h3> <p>对于大量内容的批量获取,自动化爬虫是一种高效手段。操作流程包括:</p> <ul> <li>分析网页结构,识别目标内容的HTML标签或API接口。</li> <li>利用爬虫工具(如Scrapy、BeautifulSoup)编写脚本,自动抓取目标内容。</li> <li>结合模拟登录和Cookie管理,确保爬取权限的持续有效。</li> <li>设置请求频率,模拟正常用户行为,避免被封禁。</li> </ul> <p>需要注意的是,爬取过程中应尊重网站的robots.txt政策,避免违法行为。</p> <h3>生活化视角下的建议与注意事项</h3> <p>虽然技术手段丰富多样,但绕过收费网站的行为存在一定的法律和道德风险。建议用户理性使用,尽量选择合法途径获取资源。例如:</p> <ul> <li>利用网站的免费试用或优惠活动,合理获取内容。</li> <li>关注内容提供商的促销信息,低价订阅或购买内容。</li> <li>使用公共图书馆或学校的合法资源,获取免费或低价的专业资料。</li> </ul> <p>技术手段应作为学习和探索的工具,而非非法获取内容的手段。任何绕过措施都应在合法合规的范围内进行,避免造成不必要的法律风险和道德争议。</p> <h3>总结</h3> <p>理解收费网站的防护机制是实现绕过的前提,通过模拟登录、修改网页内容、使用代理等多种技术手段,可以在一定程度上突破限制。然而,用户应始终坚持合法合理的原则,尊重内容创作者的权益。未来,随着技术的发展和法律法规的完善,网络资源的获取方式也会越来越丰富和规范。作为一名资深的软件下载站主编,建议广大用户在追求便利的同时,保持良好的网络道德与法律意识,共建健康的网络环境。</p> <h3>用户评价</h3> <p><strong>科技宅小王:</strong>我一直用模拟登录的方法绕过付费墙,操作简单效果明显,但要注意不要频繁请求,否则容易被封禁。</p> <p><strong>设计狮阿杰:</strong>通过修改网页DOM结构,成功解锁了部分隐藏内容,学习了不少网页结构知识,挺有趣的体验。</p> <p><strong>生活小白:</strong>刚开始不太懂,后来用VPN切换IP,配合脚本操作,终于拿到想看的资料,感觉技术门槛有点高,建议新手谨慎尝试。</p> <p><strong>互联网老兵:</strong>我觉得合理利用免费资源和促销活动更稳妥,绕过付费墙虽然方便,但要考虑版权和法律问题。</p>
<h3>收费网站怎么绕过:深度解析与实用技巧</h3> <p>在网络世界中,许多优质资源都被集中在收费网站上,用户需要支付一定费用才能获取完整内容或高级功能。然而,面对高昂的付费壁垒,不少用户希望找到一些方法绕过这些限制,快速获得所需资源。本文将从技术角度出发,详细介绍收费网站的常见防护机制、绕过策略以及实际操作步骤,帮助用户合理利用网络资源,同时也提醒大家遵循法律法规,合理使用网络服务。</p> <h3>收费网站的核心防护机制</h3> <p>在探讨绕过方法之前,首先需要理解收费网站的主要防护措施。这些机制旨在确保内容的专属性和商业价值,常见的有:</p> <ul> <li><strong>会员验证系统:</strong>用户必须注册并登录,才能访问付费内容。验证过程可能包括邮箱验证、手机验证或第三方登录。</li> <li><strong>付费墙(Paywall):</strong>通过前端代码屏蔽未付费用户的内容,只有完成支付后,相关内容才会解锁显示。</li> <li><strong>IP和设备识别:</strong>网站会监控访问者的IP地址和设备信息,阻止非授权设备或频繁切换IP的访问行为。</li> <li><strong>动态内容加载:</strong>利用AJAX等技术,将内容分段加载,增加绕过难度。</li> <li><strong>验证码和反爬虫措施:</strong>为防止自动化爬取,网站会设置验证码或限制请求频率。</li> </ul> <h3>常用的绕过策略与技术手段</h3> <p>针对上述防护措施,用户可以采用多种技术手段实现绕过。以下是一些常见的方法及其原理:</p> <h3>模拟登录与会话管理</h3> <p>通过模拟用户登录流程,获取有效的会话Cookie或Token,从而绕过会员验证。具体步骤包括:</p> <ul> <li>使用浏览器开发者工具,观察登录请求的参数和返回的Cookie信息。</li> <li>利用脚本(如Python的Requests库)模拟登录请求,提交正确的账号和密码。</li> <li>保存登录后获得的会话Cookie,后续请求中携带该Cookie,以获得会员权限内容。</li> </ul> <p>注意:此方法需要用户掌握一定的网络请求分析和脚本编写能力,且应确保不违反法律法规。</p> <h3>破解付费墙</h3> <p>一些网站的付费墙是由前端代码控制的,用户可以通过以下手段绕过:</p> <ul> <li>利用开发者工具,直接修改网页的DOM结构,将隐藏的内容显示出来。</li> <li>拦截请求,阻止付费验证请求的返回,模拟已支付状态。</li> <li>使用扩展或脚本,自动识别并解锁隐藏内容区域(如通过Tampermonkey脚本)。</li> </ul> <p>这种方法依赖于对网页结构的理解和一定的脚本编写能力,但也存在被反制的风险,可能导致内容显示不完整或失真。</p> <h3>绕过IP和设备限制</h3> <p>当网站通过IP或设备识别限制访问时,可以采取以下措施:</p> <ul> <li>使用VPN或代理服务器,切换不同的IP地址,规避IP封锁。</li> <li>更换设备或清除浏览器缓存,避免被识别为重复访问者。</li> <li>结合使用多用户账号,避免因单一账号频繁访问而被封禁。</li> </ul> <p>然而,频繁变换IP和设备可能引起网站的警觉,需谨慎操作,避免被封禁或追踪。</p> <h3>自动化爬取与内容提取</h3> <p>对于大量内容的批量获取,自动化爬虫是一种高效手段。操作流程包括:</p> <ul> <li>分析网页结构,识别目标内容的HTML标签或API接口。</li> <li>利用爬虫工具(如Scrapy、BeautifulSoup)编写脚本,自动抓取目标内容。</li> <li>结合模拟登录和Cookie管理,确保爬取权限的持续有效。</li> <li>设置请求频率,模拟正常用户行为,避免被封禁。</li> </ul> <p>需要注意的是,爬取过程中应尊重网站的robots.txt政策,避免违法行为。</p> <h3>生活化视角下的建议与注意事项</h3> <p>虽然技术手段丰富多样,但绕过收费网站的行为存在一定的法律和道德风险。建议用户理性使用,尽量选择合法途径获取资源。例如:</p> <ul> <li>利用网站的免费试用或优惠活动,合理获取内容。</li> <li>关注内容提供商的促销信息,低价订阅或购买内容。</li> <li>使用公共图书馆或学校的合法资源,获取免费或低价的专业资料。</li> </ul> <p>技术手段应作为学习和探索的工具,而非非法获取内容的手段。任何绕过措施都应在合法合规的范围内进行,避免造成不必要的法律风险和道德争议。</p> <h3>总结</h3> <p>理解收费网站的防护机制是实现绕过的前提,通过模拟登录、修改网页内容、使用代理等多种技术手段,可以在一定程度上突破限制。然而,用户应始终坚持合法合理的原则,尊重内容创作者的权益。未来,随着技术的发展和法律法规的完善,网络资源的获取方式也会越来越丰富和规范。作为一名资深的软件下载站主编,建议广大用户在追求便利的同时,保持良好的网络道德与法律意识,共建健康的网络环境。</p> <h3>用户评价</h3> <p><strong>科技宅小王:</strong>我一直用模拟登录的方法绕过付费墙,操作简单效果明显,但要注意不要频繁请求,否则容易被封禁。</p> <p><strong>设计狮阿杰:</strong>通过修改网页DOM结构,成功解锁了部分隐藏内容,学习了不少网页结构知识,挺有趣的体验。</p> <p><strong>生活小白:</strong>刚开始不太懂,后来用VPN切换IP,配合脚本操作,终于拿到想看的资料,感觉技术门槛有点高,建议新手谨慎尝试。</p> <p><strong>互联网老兵:</strong>我觉得合理利用免费资源和促销活动更稳妥,绕过付费墙虽然方便,但要考虑版权和法律问题。</p>
<h3>收费网站怎么绕过:深度解析与实用技巧</h3> <p>在网络世界中,许多优质资源都被集中在收费网站上,用户需要支付一定费用才能获取完整内容或高级功能。然而,面对高昂的付费壁垒,不少用户希望找到一些方法绕过这些限制,快速获得所需资源。本文将从技术角度出发,详细介绍收费网站的常见防护机制、绕过策略以及实际操作步骤,帮助用户合理利用网络资源,同时也提醒大家遵循法律法规,合理使用网络服务。</p> <h3>收费网站的核心防护机制</h3> <p>在探讨绕过方法之前,首先需要理解收费网站的主要防护措施。这些机制旨在确保内容的专属性和商业价值,常见的有:</p> <ul> <li><strong>会员验证系统:</strong>用户必须注册并登录,才能访问付费内容。验证过程可能包括邮箱验证、手机验证或第三方登录。</li> <li><strong>付费墙(Paywall):</strong>通过前端代码屏蔽未付费用户的内容,只有完成支付后,相关内容才会解锁显示。</li> <li><strong>IP和设备识别:</strong>网站会监控访问者的IP地址和设备信息,阻止非授权设备或频繁切换IP的访问行为。</li> <li><strong>动态内容加载:</strong>利用AJAX等技术,将内容分段加载,增加绕过难度。</li> <li><strong>验证码和反爬虫措施:</strong>为防止自动化爬取,网站会设置验证码或限制请求频率。</li> </ul> <h3>常用的绕过策略与技术手段</h3> <p>针对上述防护措施,用户可以采用多种技术手段实现绕过。以下是一些常见的方法及其原理:</p> <h3>模拟登录与会话管理</h3> <p>通过模拟用户登录流程,获取有效的会话Cookie或Token,从而绕过会员验证。具体步骤包括:</p> <ul> <li>使用浏览器开发者工具,观察登录请求的参数和返回的Cookie信息。</li> <li>利用脚本(如Python的Requests库)模拟登录请求,提交正确的账号和密码。</li> <li>保存登录后获得的会话Cookie,后续请求中携带该Cookie,以获得会员权限内容。</li> </ul> <p>注意:此方法需要用户掌握一定的网络请求分析和脚本编写能力,且应确保不违反法律法规。</p> <h3>破解付费墙</h3> <p>一些网站的付费墙是由前端代码控制的,用户可以通过以下手段绕过:</p> <ul> <li>利用开发者工具,直接修改网页的DOM结构,将隐藏的内容显示出来。</li> <li>拦截请求,阻止付费验证请求的返回,模拟已支付状态。</li> <li>使用扩展或脚本,自动识别并解锁隐藏内容区域(如通过Tampermonkey脚本)。</li> </ul> <p>这种方法依赖于对网页结构的理解和一定的脚本编写能力,但也存在被反制的风险,可能导致内容显示不完整或失真。</p> <h3>绕过IP和设备限制</h3> <p>当网站通过IP或设备识别限制访问时,可以采取以下措施:</p> <ul> <li>使用VPN或代理服务器,切换不同的IP地址,规避IP封锁。</li> <li>更换设备或清除浏览器缓存,避免被识别为重复访问者。</li> <li>结合使用多用户账号,避免因单一账号频繁访问而被封禁。</li> </ul> <p>然而,频繁变换IP和设备可能引起网站的警觉,需谨慎操作,避免被封禁或追踪。</p> <h3>自动化爬取与内容提取</h3> <p>对于大量内容的批量获取,自动化爬虫是一种高效手段。操作流程包括:</p> <ul> <li>分析网页结构,识别目标内容的HTML标签或API接口。</li> <li>利用爬虫工具(如Scrapy、BeautifulSoup)编写脚本,自动抓取目标内容。</li> <li>结合模拟登录和Cookie管理,确保爬取权限的持续有效。</li> <li>设置请求频率,模拟正常用户行为,避免被封禁。</li> </ul> <p>需要注意的是,爬取过程中应尊重网站的robots.txt政策,避免违法行为。</p> <h3>生活化视角下的建议与注意事项</h3> <p>虽然技术手段丰富多样,但绕过收费网站的行为存在一定的法律和道德风险。建议用户理性使用,尽量选择合法途径获取资源。例如:</p> <ul> <li>利用网站的免费试用或优惠活动,合理获取内容。</li> <li>关注内容提供商的促销信息,低价订阅或购买内容。</li> <li>使用公共图书馆或学校的合法资源,获取免费或低价的专业资料。</li> </ul> <p>技术手段应作为学习和探索的工具,而非非法获取内容的手段。任何绕过措施都应在合法合规的范围内进行,避免造成不必要的法律风险和道德争议。</p> <h3>总结</h3> <p>理解收费网站的防护机制是实现绕过的前提,通过模拟登录、修改网页内容、使用代理等多种技术手段,可以在一定程度上突破限制。然而,用户应始终坚持合法合理的原则,尊重内容创作者的权益。未来,随着技术的发展和法律法规的完善,网络资源的获取方式也会越来越丰富和规范。作为一名资深的软件下载站主编,建议广大用户在追求便利的同时,保持良好的网络道德与法律意识,共建健康的网络环境。</p> <h3>用户评价</h3> <p><strong>科技宅小王:</strong>我一直用模拟登录的方法绕过付费墙,操作简单效果明显,但要注意不要频繁请求,否则容易被封禁。</p> <p><strong>设计狮阿杰:</strong>通过修改网页DOM结构,成功解锁了部分隐藏内容,学习了不少网页结构知识,挺有趣的体验。</p> <p><strong>生活小白:</strong>刚开始不太懂,后来用VPN切换IP,配合脚本操作,终于拿到想看的资料,感觉技术门槛有点高,建议新手谨慎尝试。</p> <p><strong>互联网老兵:</strong>我觉得合理利用免费资源和促销活动更稳妥,绕过付费墙虽然方便,但要考虑版权和法律问题。</p>
<h3>收费网站怎么绕过:深度解析与实用技巧</h3> <p>在网络世界中,许多优质资源都被集中在收费网站上,用户需要支付一定费用才能获取完整内容或高级功能。然而,面对高昂的付费壁垒,不少用户希望找到一些方法绕过这些限制,快速获得所需资源。本文将从技术角度出发,详细介绍收费网站的常见防护机制、绕过策略以及实际操作步骤,帮助用户合理利用网络资源,同时也提醒大家遵循法律法规,合理使用网络服务。</p> <h3>收费网站的核心防护机制</h3> <p>在探讨绕过方法之前,首先需要理解收费网站的主要防护措施。这些机制旨在确保内容的专属性和商业价值,常见的有:</p> <ul> <li><strong>会员验证系统:</strong>用户必须注册并登录,才能访问付费内容。验证过程可能包括邮箱验证、手机验证或第三方登录。</li> <li><strong>付费墙(Paywall):</strong>通过前端代码屏蔽未付费用户的内容,只有完成支付后,相关内容才会解锁显示。</li> <li><strong>IP和设备识别:</strong>网站会监控访问者的IP地址和设备信息,阻止非授权设备或频繁切换IP的访问行为。</li> <li><strong>动态内容加载:</strong>利用AJAX等技术,将内容分段加载,增加绕过难度。</li> <li><strong>验证码和反爬虫措施:</strong>为防止自动化爬取,网站会设置验证码或限制请求频率。</li> </ul> <h3>常用的绕过策略与技术手段</h3> <p>针对上述防护措施,用户可以采用多种技术手段实现绕过。以下是一些常见的方法及其原理:</p> <h3>模拟登录与会话管理</h3> <p>通过模拟用户登录流程,获取有效的会话Cookie或Token,从而绕过会员验证。具体步骤包括:</p> <ul> <li>使用浏览器开发者工具,观察登录请求的参数和返回的Cookie信息。</li> <li>利用脚本(如Python的Requests库)模拟登录请求,提交正确的账号和密码。</li> <li>保存登录后获得的会话Cookie,后续请求中携带该Cookie,以获得会员权限内容。</li> </ul> <p>注意:此方法需要用户掌握一定的网络请求分析和脚本编写能力,且应确保不违反法律法规。</p> <h3>破解付费墙</h3> <p>一些网站的付费墙是由前端代码控制的,用户可以通过以下手段绕过:</p> <ul> <li>利用开发者工具,直接修改网页的DOM结构,将隐藏的内容显示出来。</li> <li>拦截请求,阻止付费验证请求的返回,模拟已支付状态。</li> <li>使用扩展或脚本,自动识别并解锁隐藏内容区域(如通过Tampermonkey脚本)。</li> </ul> <p>这种方法依赖于对网页结构的理解和一定的脚本编写能力,但也存在被反制的风险,可能导致内容显示不完整或失真。</p> <h3>绕过IP和设备限制</h3> <p>当网站通过IP或设备识别限制访问时,可以采取以下措施:</p> <ul> <li>使用VPN或代理服务器,切换不同的IP地址,规避IP封锁。</li> <li>更换设备或清除浏览器缓存,避免被识别为重复访问者。</li> <li>结合使用多用户账号,避免因单一账号频繁访问而被封禁。</li> </ul> <p>然而,频繁变换IP和设备可能引起网站的警觉,需谨慎操作,避免被封禁或追踪。</p> <h3>自动化爬取与内容提取</h3> <p>对于大量内容的批量获取,自动化爬虫是一种高效手段。操作流程包括:</p> <ul> <li>分析网页结构,识别目标内容的HTML标签或API接口。</li> <li>利用爬虫工具(如Scrapy、BeautifulSoup)编写脚本,自动抓取目标内容。</li> <li>结合模拟登录和Cookie管理,确保爬取权限的持续有效。</li> <li>设置请求频率,模拟正常用户行为,避免被封禁。</li> </ul> <p>需要注意的是,爬取过程中应尊重网站的robots.txt政策,避免违法行为。</p> <h3>生活化视角下的建议与注意事项</h3> <p>虽然技术手段丰富多样,但绕过收费网站的行为存在一定的法律和道德风险。建议用户理性使用,尽量选择合法途径获取资源。例如:</p> <ul> <li>利用网站的免费试用或优惠活动,合理获取内容。</li> <li>关注内容提供商的促销信息,低价订阅或购买内容。</li> <li>使用公共图书馆或学校的合法资源,获取免费或低价的专业资料。</li> </ul> <p>技术手段应作为学习和探索的工具,而非非法获取内容的手段。任何绕过措施都应在合法合规的范围内进行,避免造成不必要的法律风险和道德争议。</p> <h3>总结</h3> <p>理解收费网站的防护机制是实现绕过的前提,通过模拟登录、修改网页内容、使用代理等多种技术手段,可以在一定程度上突破限制。然而,用户应始终坚持合法合理的原则,尊重内容创作者的权益。未来,随着技术的发展和法律法规的完善,网络资源的获取方式也会越来越丰富和规范。作为一名资深的软件下载站主编,建议广大用户在追求便利的同时,保持良好的网络道德与法律意识,共建健康的网络环境。</p> <h3>用户评价</h3> <p><strong>科技宅小王:</strong>我一直用模拟登录的方法绕过付费墙,操作简单效果明显,但要注意不要频繁请求,否则容易被封禁。</p> <p><strong>设计狮阿杰:</strong>通过修改网页DOM结构,成功解锁了部分隐藏内容,学习了不少网页结构知识,挺有趣的体验。</p> <p><strong>生活小白:</strong>刚开始不太懂,后来用VPN切换IP,配合脚本操作,终于拿到想看的资料,感觉技术门槛有点高,建议新手谨慎尝试。</p> <p><strong>互联网老兵:</strong>我觉得合理利用免费资源和促销活动更稳妥,绕过付费墙虽然方便,但要考虑版权和法律问题。</p>